原文链接:https://arxiv.org/abs/2005.07162
NAT acl2020源码链接:https://github.com/mnamysl/nat-acl2020
1Intro
对于有噪输入的序列标注问题,本文提出了2种Noise-Aware Training (NAT) 方法来提高有噪输入的序列标注任务系统的准确性和鲁棒性。作者还提出了模拟真实噪声的引入。
实验部分,作者使用了原始数据及其变体,这些数据都被真实的OCR错误和拼写错误干扰。在英语和德语命名实体识别基准上的广泛实验证实,NAT始终提高了流行的序列标记模型的健壮性,保持了原始输入的准确性。
下图展示了问题和作者的方法。
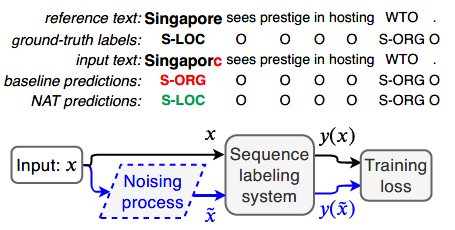
问题定义
下图给出了序列标注问题的典型结构。
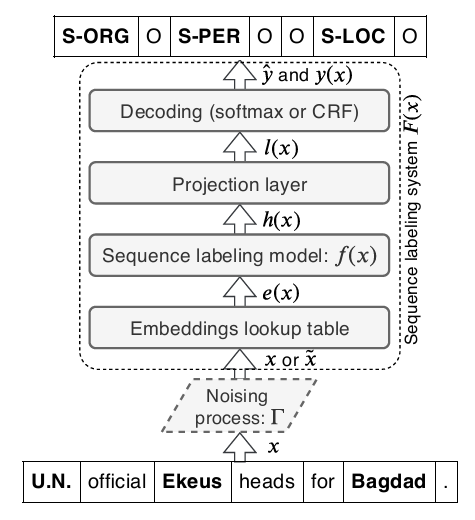
2噪声引入
作者通过引入符号
ϵ
\epsilon
ϵ 来模拟删除和插入。
噪声引入过程如下图。对于每个输入系列x,在x的每个token中的每个字符间插入符号
ϵ
\epsilon
ϵ,然后根据对应的概率分布替换字符,最后移除所有的符号
ϵ
\epsilon
ϵ,就会得到带噪的token。

3Mehod
下图中a和b分别展示了两种方法。
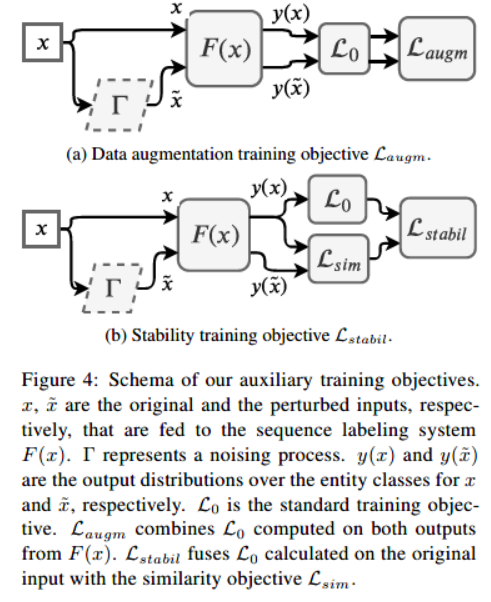
3.1Data Augmentation Method(数据增强)
作者通过在训练过程中引入各种形式的人工噪声,可以提高测试时对噪声的鲁棒性。
在训练工程中,使用2中的方法在原始序列中引入噪声,并使用clean和noisy的序列的混合,训练模型。x为输入序列,y是对应的正确标签,
θ
\theta
θ为F(x)的参数,x尖是扰动后的序列,
α
\alpha
α是损失的权重,定义损失函数如下
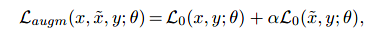
对带噪声的输入数据,模型鲁棒性更好,并保持在clean输入上表现良好的能力。
3.2 Stability Training Method(稳定训练)
(Improving the robustness of deep neural networks via stability training)括号中的文章指出了深度神经网络的输出不稳定问题。他们提出了一种针对小输入扰动稳定深层网络的训练方法,并将其应用于近似重复图像检测、相似图像排序和图像分类任务。受他们的启发,作者将Stability Training Method应用到自然语言场景中。
作者将稳定性训练目标Lstail定义如下:
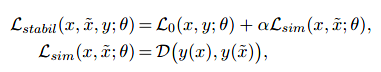
D是特定于任务的特征距离度量
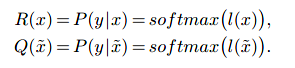
将D建模为KL散度,它衡量原始输入和扰动输入的可能性之间的对应关系:
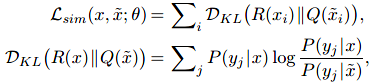
4实验
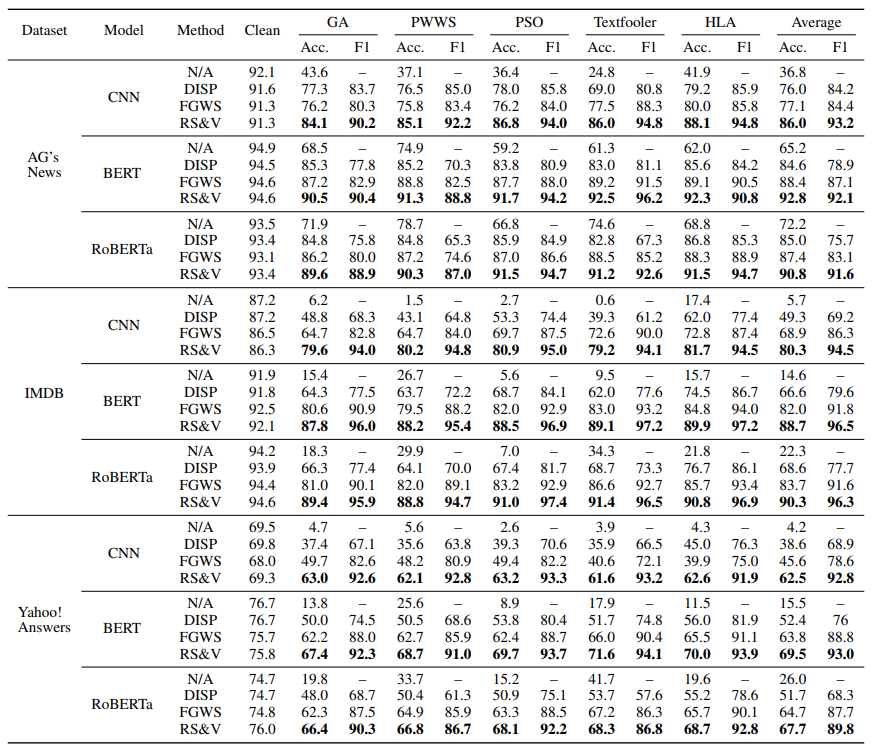
下表给出了该实验的结果。
作者发现,2种方法提高了对所有基线模型和两种语言的噪声输入数据的准确性。同时,他们保留了原始输入的准确性。数据增强的表现似乎略好于稳定性训练。
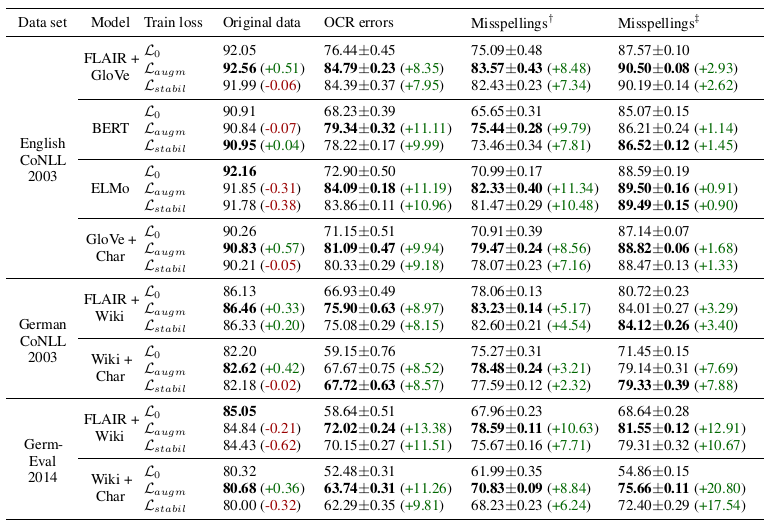
作者选择FLAIR+GloVe模型作为基准,因为它在初步分析中(上表)取得了最好的结果,表现出良好的性能。
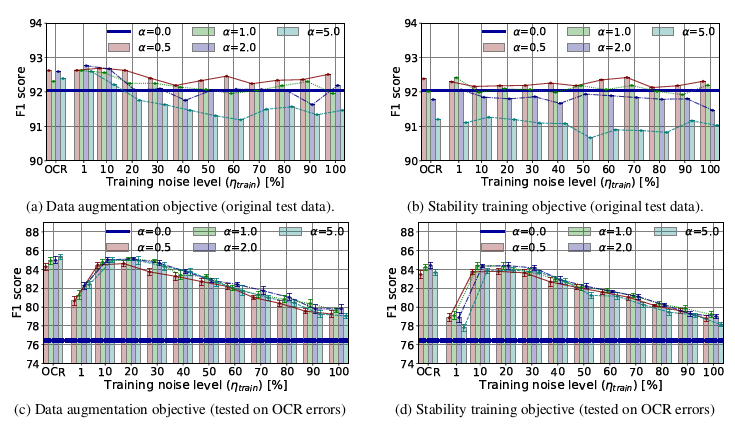
下图给出了灵敏度实验结果,基线模型
α
\alpha
α=0 。与基线相比,使用了作者NAT方法训练的模型对原始数据
的准确度基本保持,甚至提高。在受自然噪音干扰的数据上,他们的表现明显优于基线。在10%~30%的范围内,训练的准确率最高,大致相当于保留标签的噪声范围。得出结论,与完全基于干净数据训练的模型相比,在训练过程中产生的非零噪声水平(训练>0)总是能改善有噪输入数据。
α
\alpha
α最佳选择范围为0.-2.0,
α
\alpha
α=5.0在原始数据上表现出较低的性能。此外,基于真实误差分布训练的模型至多表现出稍好的性能,这表明在训练时不必知道确切的噪声分布。
为了量化作者方法带来的改进,在不同扰动级别的数据子集上测量了序列标注的准确性。此外,我们根据命名实体类对数据进行划分,以评估噪声对不同实体类型识别的影响。在这个实验,使用了英语CoNLL 2003数据集的测试部分和开发部分,并用作者的噪声处理程序引入OCR错误。下图显示了基线和建议方法的结果。
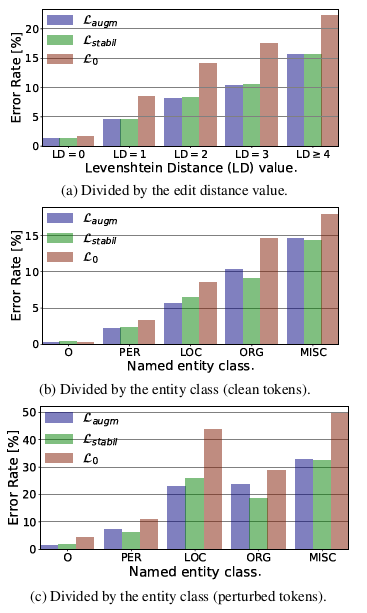
可以看出,作者的方法在所有扰动级别和所有实体类型上实现了显著的误差降低。此外,通过缩小对扰动标记的分析范围,发现基线模型对来自LOC和MISC类别的噪声标记特别敏感。作者的方法大大减少了这种负面影响。此外,由于稳定性训练在LOC类上的效果略好,而数据增强在ORG类型上更准确,作者认为这两种方法可以结合起来进一步提高整体序列标注的准确性。请注意,即使特定的token没有受到干扰,其上下文也可能是嘈杂的,这就解释了作者的方法即使对没有干扰的token也提供了改进这一事实。
future work
包括改进所提出的噪声模型(acl2021),以研究保真度对真实世界错误模式的重要性。此外,我们计划对其他真实噪声分布(例如,来自ASR)的NAT和其他序列标注任务进行评估。


![[COLING 2018] Modeling Semantics with Gated Graph Neural Networks for KBQA 阅读笔记](https://img-blog.csdnimg.cn/9d909061f81a4c58a4cd7c9a0c40e1d4.png)